
Model Details:
- Architecture:
- Frozen ResNet-18 backbone for robust features with minimal fine-tuning (2 epochs) on few (20) images of an alphabet not in learning tasks.
- 3-hidden-layer Feed-Forward Neural Network with sizes (3xN, 2xN, N), with N ≤128 neurons/layer, and fixed size across all learning tasks.
- Details:
- Parameters: Fixed hidden layers (~61,200 for N=80, ResNet-18 provides 512 input features). Also, each learned class is assigned few classification parameters.
- Memory: 5 images/class + discardable (~100) augmented images (rotations, rescalings for Omniglot). We find that an increase of the number of augmented images can lead to perfect accuracy across all tasks.
- Stability: No accuracy loss over thousands of epochs.
- Test Details:
- 20 alphabets are randomly selected from the background set of the Omniglot Dataset. Each alphabet is used for a distinct task, selecting 4 letters/classes, 5 images per class for training.
- This is a 4-way, 5-shot test on the Omniglot Benchmark dataset with no prior pretraining of any kind on task sequencing or other dataset details.
- The images are passed through the Reader to produce learnable features (512 per image).
- 10 unseen images of each of the learned classes are used for validation and testing of the trained AionMind Model with no data leakage of any sort.
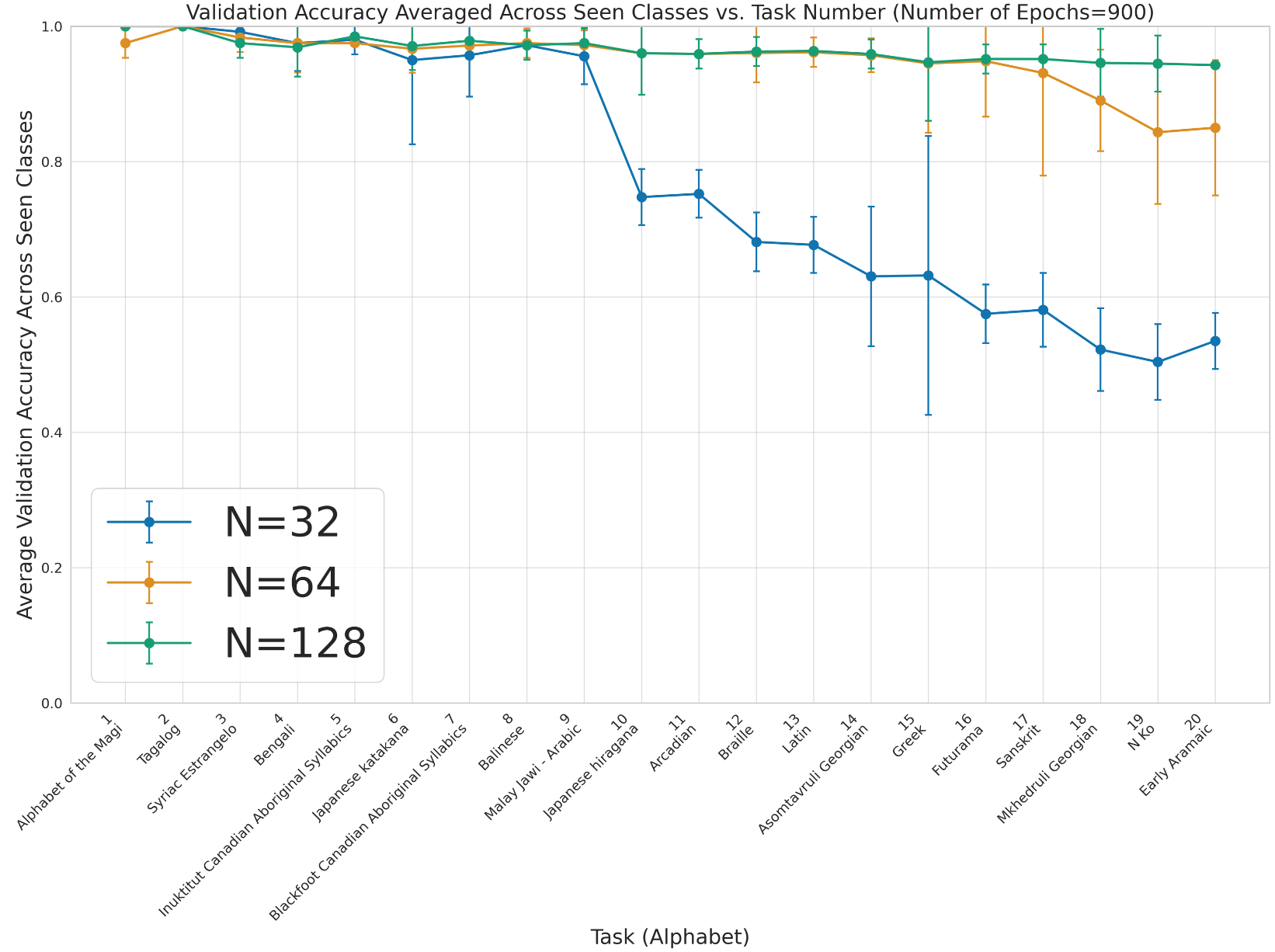
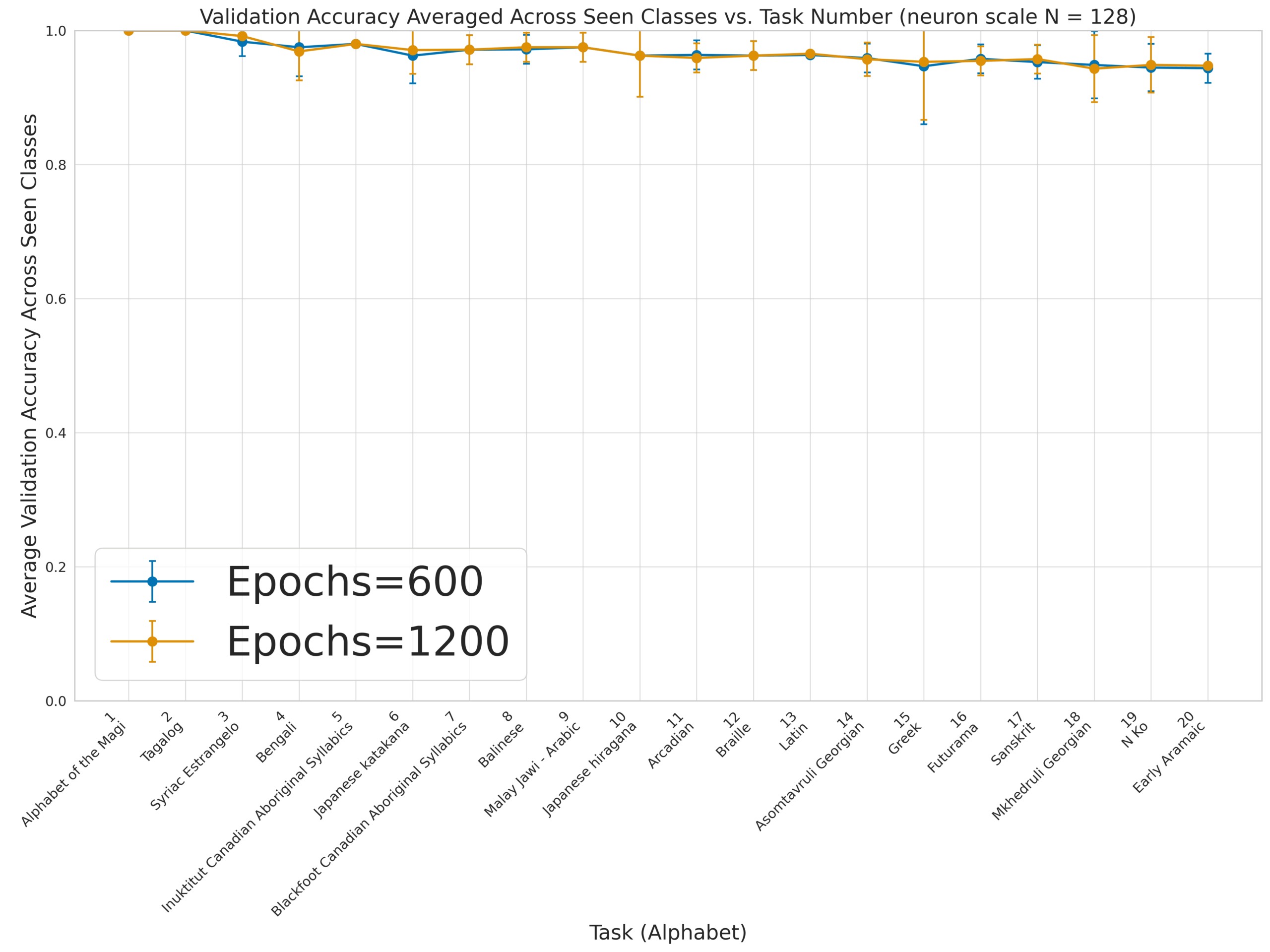
Table 1: Performance Comparison Across Methods
| System | 10-task Accuracy (Omniglot) | 10-task Forgetting | Parameters (Hidden Layers) | Memory Storage/Replay (Images/Class) | Pretraining | Stability |
|---|---|---|---|---|---|---|
| AionMind System | >95% (1-2% drop) | 0-1% | Fixed (≤100 neurons) | 3-5 | No | Thousands of epochs |
| iCaRL | ~90% (5-10% drop) | 5-20% | Dynamic, larger | ~20-100 | Yes/No | Limited |
| EWC | ~88% (8-15% drop) | 8-25% | Dynamic, larger | None | Yes/No | Limited |
| GEM | ~92% (3-7% drop) | 3-20% | Dynamic, larger | ~20-100 | Yes/No | Limited |
| SimpleShot | ~94% (non-continual) | N/A | Fixed, larger | N/A | Yes | N/A |

Future Benchmarks:
- CIFAR: Targeting >90% accuracy on CIFAR-10/100, demonstrating scalability to complex datasets.
- Noisy Images: Testing robustness to noise (e.g., Gaussian, blur), ideal for real-world applications.
Commercial Value:
- Cost-efficient: Minimal parameters and memory reduce hardware costs.
- Scalable, Fast and Efficient.
- Robust: Stability over thousands of epochs suits lifelong learning.
- Flexible: No pretraining enables rapid deployment across domains.